想知道BIBFRAME的类Hub(bf:Hub)究竟是什么?博文比较长,先说个人结论:bf:Hub是内容表达(或内容表达组)。间接佐证:bf:Hub在2021年发布时定义为bf:Work的子类,现在bf:hasExpression属性仍同时用于bf:Hub和bf:Work类。
- 背景
1997年国际图联(IFLA)《书目记录的功能需求》(FRBR)提出书目资源四层实体“作品—内容表达—载体表现—单件”(后常简称WEMI),2017年取代FRBR系列的《IFLA图书馆参考模型》(IFLA LRM)继承此模型。本文中不加限定说明的WEMI均为LRM概念(为方便以lrm:标识),如标题中的“作品”即指lrm:Work。
美国国会图书馆(LC)的BIBFRAME 2.0模型是三层核心类“作品—实例—单件”,bf:Work对应lrm:Work+lrm:Expression。当BIBFRAME 2.1和2.3词表新增bf:Hub(作为两部作品之间桥梁的抽象资源),形成“Hub—作品—实例—单件”四层基本模型类(Basic Model Class),似乎正对应LRM的四层,但BIBFRAME 模型图现在仍是2.0版,没有Hub类。
这2个四层实体/类真是一一对应吗?bf:Hub相当于lrm:Work吗?尽管有人这么并列,我之前也这么认为,但每每看到bf:Hub记录,总有点怀疑。上月博文“Bibframe Hub 聚类现状”(2024-9-16,/posts/2024/0916/6303),着重于单条bf:Hub记录,看其侧栏关联的记录。这次希望更详细了解bf:Hub本身,选择原语种为英语的《哈姆雷特》及其中译、《红楼梦》及其英译,略做探究。由于上文所引Nate Trail,bf:Hub数据来自LC相应的规范记录,因此与规范库 (authorities.loc.gov)对照。
- [1] 作品规范记录对应lrm:expression?
BIBFRAME 2.0 模型只有三层Work—Instance—Item。规范记录对应Bf:Work,书目记录对应bf:Instance,感觉很完美。
如果bf:Hub数据来自LC相应的规范记录。难道规范记录对应bf:Hub?
LC规范库,作品的规范记录大多通过名称-题名查找,少数(如匿名作品)通过题名查找。以莎士比亚《哈姆雷特》为例,查:Shakespeare, William, 1564-1616 hamlet,现有108条结果,约60条标记为规范标目,含中译3条。以下为其中4条:
Shakespeare, William, 1564-1616 hamlet(主记录,关联460条书目记录)
Shakespeare, William, 1564-1616. Hamlet. Chinese(中译,关联1条书目记录)
Shakespeare, William, 1564-1616. Hamlet. Chinese (Lin)(林同济中译,未关联书目记录)
Shakespeare, William, 1564-1616. Hamlet. Chinese (Zhu)(朱生豪中译,未关联书目记录)
LC的题名/名称-题名规范用于书目记录的130/240等字段,同一作品常有多条记录(如上,有不同语种、同一语种不同译本,以及不同选本、部分,等等)。因此作品规范记录显非lrm:Work,更接近lrm:expression。
按编目规则,文献原语种不加语种限定,因此仅有题名、无任何限定的那条记录(我暂称为“主记录”),可对应LRM的代表性内容表达,而非lrm:Work,在规范记录中应该也没有字段给予特别标识。
那么,是不是bf:Work对应lrm:expression,bf:Hub对应lrm:Work?
- [2] bf:Hub对应什么?
以前大致浏览过bf:Hub检索结果一览,感觉并没有合并相同作品。如前所引,bf:Hub数据来自LC相应的规范记录。从LC规范库与关联数据服务(id.loc.gov)的查询结果对比,两者大部分形式一致,但bf:Hub的结果数(82条)比规范记录数(约60条)还要多出不少。以下1条对应于规范库“主记录”:
Shakespeare, William, 1564-1616 hamlet(主记录)Identified By:Lccn: n80008522
由两者的名称-题名形式对比,推测多出来的那些bf:Hub,应该来自未使用规范形式的书目记录(这些bf:Hub记录中没有LCCN规范记录ID)。回顾先前博文“Hub:BIBFRAME模型下的超级作品”(2020-6-28)/posts/2020/0628/5427,其中所引2019年欧洲BIBFRAME研讨会上Kevin Ford关于bf:Hub的MARC来源的介绍,正是这么说的。可是由于当初的博文误读,结论和标题完全错误。
换言之,目前bf:Hub不只对应原有的规范记录以及规范库结果,离lrm:Work距离更远。
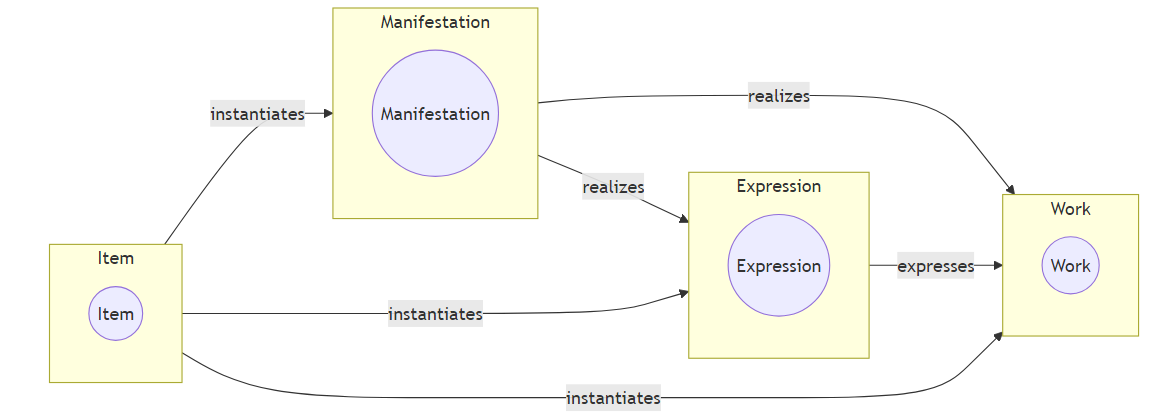
- [3] 四层关系Hub—Work—Work—Instance
特别奇怪的是,从BIBFRAME各类记录侧栏的关系追溯,通常竟然有4层(如果加上Item的话就是5层模型了):
Hub(has Expression)Work(has Expression)Work(has Instance)Instance
猜测在有bf:Hub前,bf:Work兼作品/内容表达,因此有两层?好奇前一层Work的数据何来。另外从数据看,bf:Hub像某种内容表达组。
- 以《哈姆雷特》主记录为例:
【Bibframe Hub】(有LCCN,对应规范记录)
https://id.loc.gov/resources/hubs/83e65f55-ac8f-fcb8-ea65-120fbbbaccec.html
Title = Hamlet
Identified By = Lccn: n80008522
侧栏:Has Expression = Shakespeare, William, 1564-1616 Hamlet(数十条/名称形式相同,此为第1条)
【Bibframe Work】(无ID,来源不明;与下条“分类号”不同)
https://id.loc.gov/resources/works/7624041.html
Title = Hamlet
Classification = LCC: PR2795.M3 H38
侧栏:Has Expression = Shakespeare, William, 1564-1616 Hamlet, 1751(数十条/名称形式各异,此为第1条)
【Bibframe Work】(无ID,URL标识同instance,对应书目记录)
https://id.loc.gov/resources/works/10026252.html
Title = Hamlet, 1751
Classification = LCC: PR2878.H3 K5 1751a
侧栏:Has Instance = Hamlet, 1751(一条)
【Bibframe Instance】(对应书目记录)
https://id.loc.gov/resources/instances/10026252.html
Title = Hamlet, 1751
Identified By = Lccn: unk84045293
- 仅偶尔遇3层,即:Hub—Work—Instance
如《哈姆雷特》规范标目中未注明中译者的那条Shakespeare, William, 1564-1616 Hamlet. Chinese(仅1条书目记录)
【Bibframe Hub】(有LCCN,对应规范记录)
https://id.loc.gov/resources/hubs/35bf8775-775a-4808-8ba0-6d52396cf7a1(长标识)
Title = Hamlet. Chinese
Identified By = Lccn: no2016051867
Note = Data source: (hdg.: 哈姆雷 = Hamulei ; translator, Peng Jingxi)
侧栏:Has Expression = Shakespeare, William, 1564-1616 Hamuleite
【Bibframe Work】(无ID,URL标识同instance;译者与Hub不同)
https://id.loc.gov/resources/works/23394582.html
Title = Hamuleite
Contribution = Fu, Guangming, 1965- (Translator)(傅光明)
侧栏:Has Instance = Hamuleite
【Bibframe Instance】(对应书目记录)
https://id.loc.gov/resources/instances/23394582.html
Title = Hamuleite: Hamlet
Identified By = Lccn: 2023388166 = Isbn: 9787201123844
- [4] 遗留数据问题
大规模的数据往往经不起细察。曾说自己手黑,随便一查就会发现错误问题。当年关注OPAC 2.0,发现新功能常使一些原本隐藏的数据错误显现出来。这次也一样,上述《哈姆雷特》记录汉译者有问题;《红楼梦》(Cao, Xueqin, approximately 1717-1763,用姓名查可包含各种变异题名结果),看到各种版本混在一起,不同英译本被聚合在一个bf:Work下。
前述[2]中多出来的bf:Hub记录,凸显遗留数据未采用规范形式的问题。[3]中的聚合匹配错误,同样体现数据的各种问题,不一定是错误,也可能由于编目规则的逐步进化。如果通过细化不同时期MARC记录到BIBFRAME的转换规范,减少数据形式上的差异,或有助于降低聚合处理难度。