WEMI是作品(Work)、内容表达(Expression)、载体表现(Manifestation)和单件(Item)的首字母缩略词,出自1997年《书目记录的功能需求》(FRBR),由2017年《国际图联图书馆参考模型》(IFLA LRM)继承,是书目资源描述领域著名的层次模型。
以曹雪芹的《红楼梦》为例说明之。《红楼梦》本身是作品,120回本和80回本、印刷版和语音版等是不同的内容表达,各出版社《红楼梦》版本是不同的载体表现,一套印刷版《红楼梦》是单件。如此标记的结果是,原本关系不明确的各种《红楼梦》书目记录,相互间有了明确的层级关系,在书目数据呈现时可以进行多样化的聚合,有助于用户选择适合自己需求的版本。
WEMI模型不仅适合于描述图书,对其他非物质文化资源也同样适用。比如罗丹的雕塑《思想者》,有多个不同的翻模版,可视为不同的内容表达,当然它同时也是载体表现和单件,对《思想者》拍摄形成的照片则是不同的内容表达/载体表现,如此等等。openWEMI就是希望把WEMI模型扩展到图书馆领域之外。
2023年末,openWEMI发布草案。参见:开放WEMI(openWEMI)提案发布(2023-12-14)
近日,正式词表发布:OpenWEMI vocabulary(https://ns.dublincore.org/openwemi/)
OpenWEMI由都柏林核心元数据倡议(DCMI)支持,显然目标是如都柏林核心(Dublin Core, DC)一样、成为具有超出图书馆界影响力的通用模型。作为一种元模型,对于没有采用WEMI模型的各种元数据标准,可以使用OpenWEMI为需要描述的资源增加层次关系。
按其介绍:OpenWEMI是一个最小约束词表,用于使用作品、内容表达、载体表现、单件等概念描述创建的资源。
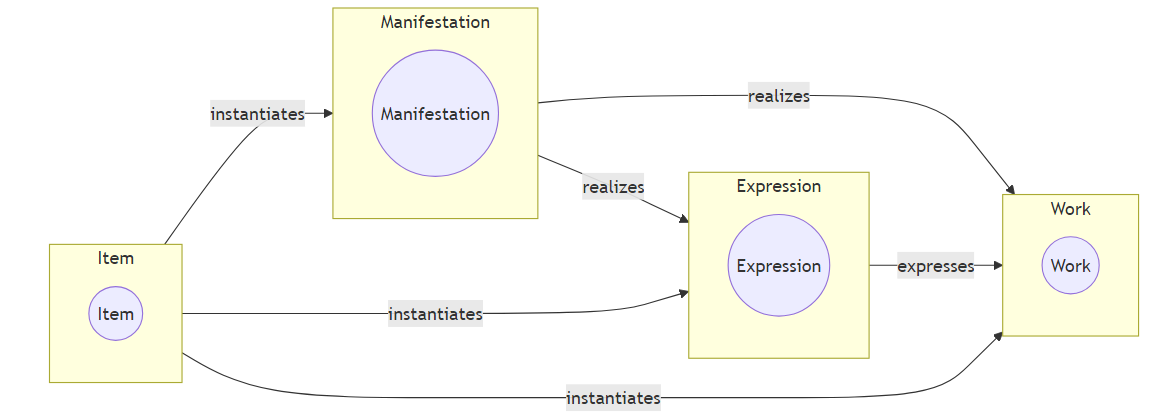
与去年提案相比,正式发布的OpenWEMI是一个很纯粹的WEMI模型,排除了责任实体及其属性,只含资源及其关系:
类5个:超级类Endeavor,4个子类即WEMI
- Endeavor(一种创作)
- Work(艺术或智力创作的抽象概念)
- Expression(可感知的创作形式)
- Manifestation(创作的物理体现)
- Item(创作的示例)
属性15个:包括主要关系、共同关系和相关关系。
- related Work相关关系
- related Expression
- related Manifestation
- related Item
- expresses主要关系
- expressed by
- manifests【用于WE类/非仅E类】
- manifested by
- instantiates【用于WEM类/非仅M类】
- instantiated by
- common Endeavor共同关系
- common Work
- common Expression
- common Manifestation
- common Item
相关关系认定很宽松。共同关系则是FRBR没有的,指示两个资源表示或包含相同的 openWEMI 实体。
作为“最小约束词表”,主要关系与FRBR有所不同,不严格要求 W—E—M—I 环环相扣,可以省略中间层,如下图,可以W-E-I或W-M-I等(换言之也可以只分3个层次,因为有的领域很难分出4个层次)。下图出自openWEMI的GitHub主页(https://github.com/dcmi/openwemi,目前还是提案内容,但“主要关系”没有变化):