图书馆编目有两种,即所谓原编(原始编目)和套录(复制编目)。原编指对没有书目记录的资源进行编目;套录指复制已有书目记录,如有问题则修改。传统上,馆藏的所有书目记录都保存在本馆系统中(即使是云存储)。随着BIBFRAME的引入,这种模式可能会变化了。
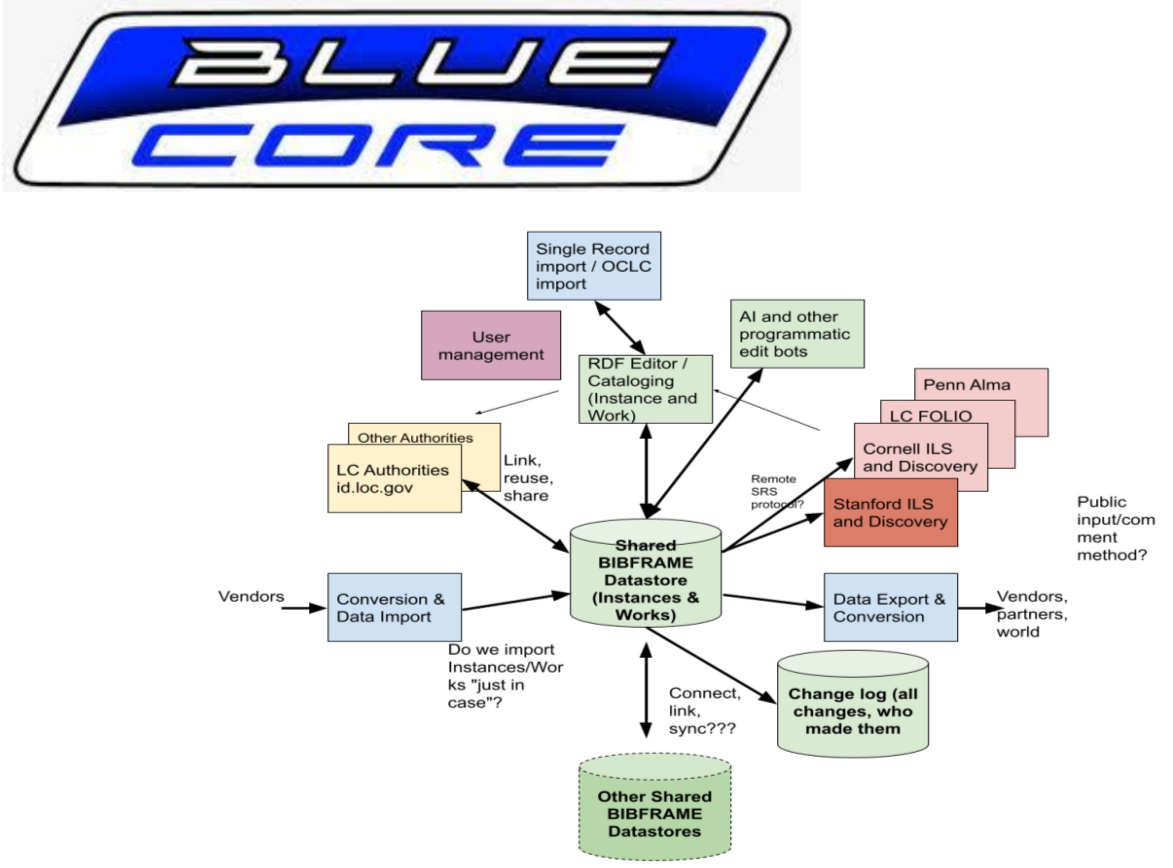
LD4是美国始于2015年的图书馆关联数据系列项目,2023年为LD4P(Linked Data for Production)第4阶段,康奈尔、斯坦福、宾州大学和美国国会图书馆为在生产环境中推进BIBFRAME,提出了一个转变编目模式、停止套录数据的蓝色核心计划(Project Blue Core),数据将放在一个机构共享的中央数据池中,不下载到本地,如需修改、也只修改数据池中的记录。计划将分3个阶段实现:第一阶段—构想(2023年秋),第二阶段—最终计划(2024年), 第三阶段—实施(2025年)。
目前只在2023欧洲BIBFRAME研讨会报告上看到介绍:
生产关联数据第4阶段:在机构中立的数据池中真正共享数据 Linked Data for Production Phase 4: Truly Shared Data in an Institutionally Neutral Data Pool / Philip E. Schreur, Tom Cramer, Jason Kovari, Simeon Warner. BIBFRAME Workshop in Europe 2023. 11 slides. https://www.bfwe.eu/attachments/bfwe23-schreur-cramer-kovari-warner.pdf
PPT比较简洁,详细了解需要结合47分钟音频(https://youtu.be/hoWk1vcvsi4)。互动从23分钟开始,内容:你认为真正共享和维护描述性元数据在政治上是可能的吗?元数据应该被锁定开放(locked open)吗?你认为这种方法最初会遇到什么问题?
【架构图】