《数据信息素养》(Data Information Literacy: Librarians, Data, and the Education of a New Generation of Researchers)一书2015年1月由普渡大学出版社出版,汇编了普渡大学、明尼苏达大学、俄勒冈大学和康奈尔大学为研究生开发数据信息素养课程所用的不同策略与方法。书中包含上述大学的5个实施案例,以及供对开发DIL课程有兴趣的图书馆员用“DIL工具包”或手册。
该书是IMLS项目成果之一,建有网站 DIL (data information literacy) 公开相关信息。查了下,应该是2011年Purdue大学的项目,资助金额249,391美元。
该书第9章“开发数据信息素养课程:大学图书馆员指引”在项目网站上开放获取:
Developing Data Information Literacy Program: A Guide for Academic Librarians
本章以图9“开发信息素养课程的步骤”为纲撰写,课程内容是为研究生开设的“研究数据管理”课程,感觉是针对各学科的、并非适合所有学科的泛泛课程。主要从馆员个人角度考虑具体如何开发DIL课程,基本不涉及馆领导的宏观决策层面。从案例看,5个团队采用5种不同教学形式:小课程、在线课程、一次性讲座、嵌入馆员、系列讲座。当然,开发过程还是一样的。
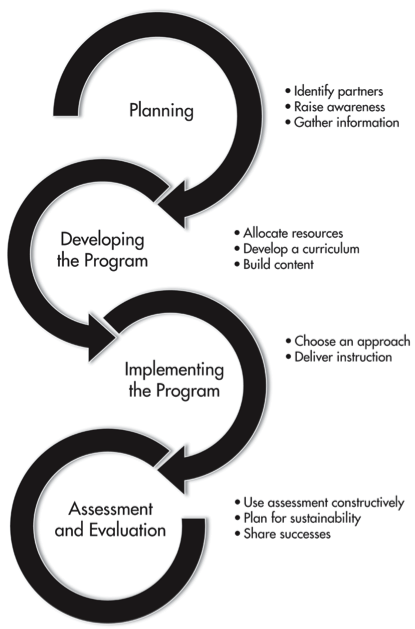
FIGURE 9.1 Stages of developing a data information literacy program导言
馆员为什么要教DIL技能?
【1】规划
– 如何发现合作者
– 如何推广DIL、提高知晓
– 我们的经验(收集信息:了解需求、环境扫描,了解并与教师合作/研究生合作)
【2】开发课程
– 可用资源
– 开发课程(开发学习成果、计划学习评估)
– 建设课程内容
【3】实施课程
– 选择方法(表9.1 DIL教学方法的优缺点:小课程、在线课程、一次性讲座、嵌入馆员、系列讲座)
– 提供教学(排课、学生反馈、维持双方兴趣】
【4】评估和评价
– 建设性使用评估
– 规划可持续性
– 发现什么有用(并分享成功)(图书馆员工/学科馆员参与,可扩展的交付工具,力争上游)
结论
参考文献
——— 开发课程的方法 ———
“开发课程”过程中,考察学生是否掌握所传授的知识是很重要的部分。看到2个以前不了解的方法,大致上前者可用于设计考题或者考察学习重点,后者可当作随堂测试方式:
– 开发学习成果:布鲁姆分类法(Bloom’s taxonomy – Wikipedia)
“好的学习成果是具体的、可衡量或可观察到的、清晰的、符合活动和评估、以学生为中心而非以讲师为中心的。同时也指定学生表现的准则和水准,以行动动词开始。布鲁姆分类法是出色的行动动词来源,广泛用作分类目的和成果的教育工具。”
– 计划学习评估:一分钟练习(1-minute paper 或 One-Minute Paper)
搜索引擎查询,可知很多大学在采用,比如加拿大爱德华王子大学写作委员会所做简介,比上述链接的说明简洁,其后半部分涉及用于评估:
One-Minute Papers can also be used as a Classroom Assessment Technique at the end of a class. Direct the students to answer two questions: “What was the most important thing that you learned during today’s class?” and “What important question do you still have?” This requires the students to evaluate what they remember and to reflect on how well they understand the material. Their responses can provide you with insights into how they are learning (or misunderstanding) the material.