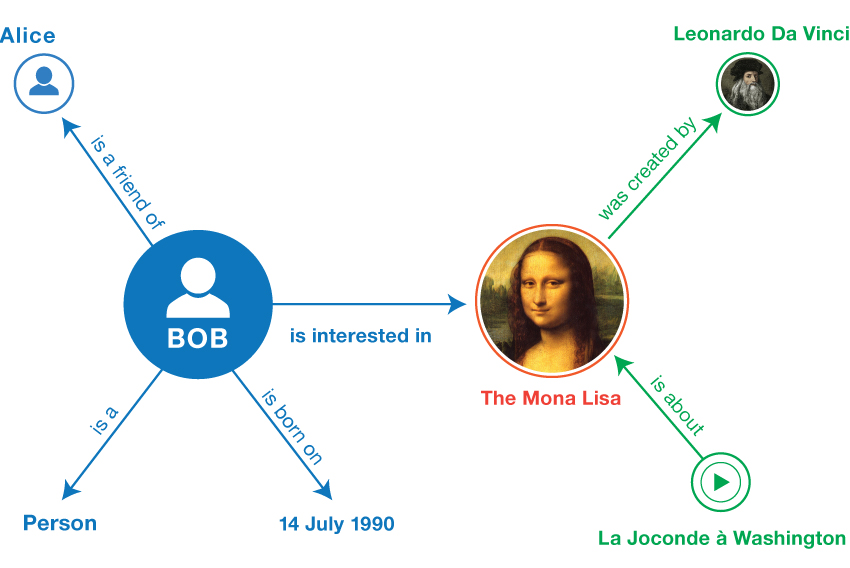
Samvera原名Hydra,是一个开源的机构库解决方案(由Fedora机构库软件、Solr索引、Blacklight分面搜索浏览定制显示界面和Samvera集成组件4个部分构成)。最初是Hull、Stanford、Virginia三所大学的跨机构项目,现在已形成一个参与广泛的开发社区。
上月Samvera MODS to RDF Working Group发布《MODS到RDF映射建议》1.0版,定位是非官方的应用纲要/应用配置文件(Application Profile)——MODS本身有官方RDF但一直处于草案阶段(参见:MODS到BIBFRAME映射,2019-2-15)。
Kathleen Gerrity在MODS和BIBFRAME邮件组发消息,如此介绍《MODS到RDF映射建议》:
本应用纲要提供对数字对象映射MODS XML元数据到RDF关联数据类和属性,使用广泛采用的RDF命名空间。
十多家学术和公共图书馆成员协作成果,文件包含MODS元素到RDF的综合映射,使用真实世界元数据用例和数百样例。
不同于使用单一词表或新提出正式本体来实施直接的XML到RDF方法,本映射包含来自大量现有词表的属性,为关联数据环境中的记录提供更大价值。提供直接的“直接”映射(不需要为诸如主题、人或地点之类的概念创建本地对象)和更彻底的“铸造对象”(minted object)映射。
尽管工作在Samvera数字机构库框架下实行,本映射与系统无关,希望在广泛环境下可应用。
via [MODS]邮件组: MODS to RDF Mapping Recommendations now available / Kathleen Gerrity (2019-2-12)
本建议重用22个命名空间,包括少数自定义属性采用的不透明命名空间(OpaqueNamespace,开源社区支持的本体框架,提供永久URI)。有些命名空间仅采用一二个属性(如基础的owl, rdf, rdfs, skosxl)。非图书馆领域开发的词表主要用于相关项(mods:relatedItem)。
另外用到多个LC代码表,不是作为取值,而是作为属性,如以关系词代码作为属性,涉及责任者、出版发行项以及馆藏机构——尤其是出版发行机构与地点采用关系词代码,感觉脑洞比较大:
直接映射例2:
<https://example.org/objects/1> relators:pup <http://vocab.getty.edu/tgn/7013445> ;
relators:pbl “published by John P. Soule” ;
bf:editionStatement “3rd edition” ;
dcterms:created “1930?” .
——《MODS到RDF映射建议》摘译——
MODS to RDF Mapping Recommendations (v.1.0) / Samvera MODS to RDF Working Group. January 2019
背景与需求
2015年中,为升级到Fedora 4,必须由基于XML、存储为数据流的元数据,转换到存储为RDF属性的元数据。许多机构大量使用MODS XML,但MODS不易翻译为RDF图模型,除非使用空节点(在Samvera和Fedora中有问题),或为元数据元素(如创作者和主题)铸造对象类(minted object classes)。因此前波士顿公共图书馆的Steven Anderson创建MODS到RDF工作组,提出创建创建一个社区设计的应用纲要,映射MODS描述元数据到RDF。
战略与决定
评估发现MODS RDF本体不合需要:[1]缺少积极维护;[2]实施中过于依赖使用空节点和/或铸造对象;[3]缺乏机构采用。
决定选择使用已在其他关联数据数据集中广泛使用的各种词表,将MODS XML元素映射到RDF。
虽然使用如此多不同的词表[见后]增加了映射指南的复杂性,但这种方法可以比作“不把所有鸡蛋放在一个篮子里”的想法。虽然机构必须准备评估许多词表的当前和未来稳定性,但如果一个词表不再受支持或进行主要版本更改,只需要更新这些映射的一部分,而不是整个文档。
早期考虑采用MODS RDF、BIBFRAME(从v.1到v.2)、都柏林核心元素和都柏林核心术语,但发现不足以表达必要的面向机构库的内容概念,或者与Fedora 4环境中的实现不合。进而研究其他词表如Schema.org、FOAF、SKOS、BIBO和RDA等。
分析过程
参与机构分别对20个MODS顶层元素如何映射逐个进行确认并提供样例等,由小组从以下方面评审,[1]数据保真度、[2]可接受的损失、[3]特定命名空间的相对优点(如采用率、预计未来可行性)、[4]遵守属性的定义域和值域取值的必要性、[5]实现的复杂性,最终达成共识。某些元素有简单和复杂两种选项。
偶而在通用命名空间找不到合适映射,小组建议在不透明命名空间(OpaqueNamespace,http://opaquenamespace.org/开源社区支持的本体框架,提供永久URI)中提出新的谓词,但目前这些谓词[属性]尚未在OpaqueNamespace中注册。
映射建议
映射分为两大类:直接映射(简单选项)和铸造对象映射(复杂选项,限部分元素)。
直接映射(简单选项)提供从MODS XML元素到RDF语句(主体、谓词、客体)的映射,且无需为主题、人物、事件或地点等概念创建或维护本地对象。所有语句都以源自外部词表(例如LCSH)的URI或文字值(文本字符串)结尾。可以使用所描述的数字对象直接存储、维护和更新这些RDF语句。此法简单,但有时会丢失MODS记录的粒度和细节,因为并非每个数据点都可以直接映射到RDF属性。
铸造对象映射(复杂选项)为该MODS元素(题名对象、名称对象等)创建本地概念对象(必须由本地机构库系统维护),以替代使用空白节点。本地对象具有单层RDF语句(主体、谓词、客体),它们提供源自外部词表的URI、本地对象的URI或文字值(文本字符串)。与所描述的数字对象一起存储的RDF语句是指向这些本地概念对象的指针。此选项允许将MODS记录中的所有详细信息序列化为RDF,以用于复杂的MODS元素如名称和主题。
铸造对象增加了数据模型的复杂性,但描述性书目元数据本身就很复杂。【直接映射中客体取文字值的较多,但】书目或文化遗产本体中使用的许多RDF谓词都具有URI或其他RDF对象类型的定义值域(可接受值的类),而不是字符串文字。本文档中的映射力求遵守所有示例中定义的值域,这需要为未由现有URI表示的概念、题名、人员、地点、馆藏或组织创建本地对象。
本映射中,某些情况提供多种方式映射元素或值【元素选择不多,值URI选择较多】。机构应创建并维护本地应用配置文件,以记录最适合其自身数据、应用和用户需求的方法。
使用命名空间
BIBFRAME (v.2) 【LC。用于mods:recordInfo;另外铸造对象的类多采用BF2】
The Bibliographic Ontology (BIBO)【用于mods:relatedItem】
Classification Schemes classSchemes【LC。用于mods:classification】
DBPedia Ontology【用于mods:relatedItem】
Dublin Core Metadata Element Set, Version 1.1
DCMI Metadata Terms
DCMI Type Vocabulary
EBUCore【用于mods:relatedItem】
Europeana Data Model (EDM)
FOAF (Friend of a Friend)【foaf:name;铸造对象的类:foaf:Person,foaf:Organization,foaf:Agent】
GeoJSON-LD【坐标 geojson:bbox,geojson:coordinates,用于mods:subject】
MARC Code List for Relators【LC。大量采用关系词作为属性:各种责任者,出版发行生产制作地、者,收藏机构rps=Repository】
OpaqueNamespace【不透明命名空间】
OWL 2【owl:sameAs】
Portland Common Data Model【用于mods:relatedItem】
RDA Unconstrained
The RDF Concepts Vocabulary (RDF)【rdf:type】
RDF Schema 1.1【rdfs:label,rdfs:seeAlso】
Schema.org
SKOS (Simple Knowledge Organization System)【skos:note;skos:exactMatch,skos:closeMatch,skos:relatedMatch;类:skos:Concept】
SKOS eXtension for Labels【skosxl:prefLabel,用于mods:titleInfo,mods:subject】
Standard Identifiers Scheme【LC。大量采用】
直接映射(简单选项)【仅摘<mods:titleInfo>片断】
dcterms:title 文字
dce:title URI
dcterms:alternative 文字
例1:题名含不排序字符及子题名
<https://example.org/objects/1> dcterms:title “The wintermind : William Bonk and American letters” .
例6:统一题名
<https://example.org/objects/1> dce:title <http://id.loc.gov/authorities/names/n00020514> .
铸造对象映射(复杂选项)【仅摘<mods:titleInfo>片断】
类:bf:Title
dce:title URI
bf:variantType 文字
rdfs:label 文字
skos:note 文字-编目员提供题名
skos:relatedMatch URI-规范题名
skosxl:prefLabel URI-首选题名
例1:题名含不排序字符及子题名
<https://example.org/objects/1> dce:title <https://example.org/titles/1> .
<https://example.org/titles/1> a bf:Title ;
rdfs:label “The wintermind : William Bonk and American letters” .
例6:统一题名
<https://example.org/objects/1> dce:title <https://example.org/titles/1> .
<https://example.org/titles/1> a bf:Title ;
rdfs:label “Bible” ;
skos:relatedMatch <http://id.loc.gov/authorities/names/n00020514> ;
bf:variantType “uniform” .