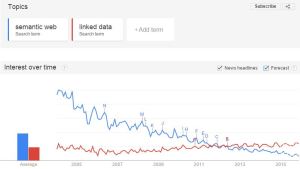
十月下旬,几乎同时发生了两件与研究者标识(ID)相关的事。一是中科院文献情报中心建立ORCID中国平台,一是高校系统成立“中国大学学者标识建设及服务推进工作组”(后者未见报道,感谢云影提供会议资料)。与之密切相关的,是几个围绕研究者信息的系统,一是清华大学的“清华学者”网,一是中科院“中国科学家在线”(iAuthor)——系统看上去就像升级版的机构库。
正在此时,看到了OCLC副总裁Lorcan Dempsey在差不多时间发表的长篇博文,全面介绍“研究信息管理系统”——这不正是类似升级版机构库的系统吗?或许因为Dempsey是英国人,不那么美国中心,常在博文中介绍美国以外的事情。RIM就是先流行于美国以外的大学,而美国现在也开始感兴趣了。
博文信息量很大。其中对于图书馆,可以认为其中心思想是:大学里对研究信息管理感兴趣的机构很多,图书馆要抓住机会,进一步参与支持大学的研究生活。这与我的想法很合拍。
以下为摘编译。
———-研究信息管理系统——一种新的服务类别?———-
Lorcan Dempsey’s Weblog: Research information management systems – a new service category? (2014-10-26)
近年兴起的“研究信息管理”(RIM,Research Information Management),由“研究信息管理系统”(RIMs)支撑,早年称作“当前研究信息系统”(CRIS,Current Research Information System)。
【RIM:目标、成果、动机】
RIM指有关研究生命周期和参与实体(如研究者、研究成果、机构、资助、设施……)信息的集成管理。目标是在大学各部分同步数据,减少所有参与研究过程数据收集和管理者的负担。成果是提供对机构研究活动更大的可见度。动机包括更好的内部报告和分析,支持合规管理与评估,通过对研究专长与成果的有组织的披露,改善声誉管理。
【功能】
* 【资助】奖项管理与奖项机会识别。匹配潜在资助源的兴趣,支持资助与合约活动的管理与沟通。
* 出版管理。收集关于研究者出版物的数据。常通过搜索外部来源(如Scopus和WOS)帮助填充文档,提供通告保持更新。
* 专业简历的协调与发布。集中维护专业简历。从不同系统抽取数据。可能用于内部报告或评估目的,支持为研究者个人提供各种所需表格的个人数据(例如不同资助机构),用于通过机构研究门户等发布到网上。
* 研究分析/报告。提供关于研究活动和研究兴趣的管理信息,跨系、小组和个人。
* 遵从内部/外部规定
* 支持开放获取。与机构库同步,管理存储需求,与开放获取政策的信息源集成。
【软件】产品
-主要产品
–爱思维尔的Pure
–汤森路透的Converis
—Symplectic Elements(有麦克米伦出版社背景)
-相关产品
—infoEd Global(电子研究管理)
—Ideate(研究管理应用的综合套件)
—VIVO(发现跨机构研究者,开源语义网应用)(Pure和Symplectic可接口至VIVO)
— Kuali Coeus for Research Administration(研究管理综合系统,开源)
-机构库扩展
DSpace和Eprints都写了扩展,提供某些类似RIMs的支持。例如Dspace-Cris扩展了Dspace模型以迎合Cerif实体【见“标准”】,基于为“香港大学学术库”所做的工作。
标准【2种数据格式】
– CERIF(Common European Research Information Format):通用欧洲研究信息格式,来自EuroCRIS(欧洲国际研究信息组织),提供RIM系统间数据交换格式
–Casrai词典(Consortia Advancing Standards in Research Administration Information):推进研究管理信息标准联盟词典
【已上线的系统】
-国家级
–南非:DST/NRF RIM(科技部与国家研究基金研究信息管理系统)
–挪威:CRIStin(挪威当前研究信息系统)
–荷兰:Metis(研究信息数据库)
-机构级
–伦敦大学皇家霍洛威学院【使用Pure,大学计算中心负责】
–香港大学:发展机构库,包含RIM或CRIS特性【HKU Scholars Hub(香港大学学术库)】
–英国阿伯丁大学:同时有RIM和IR(更常见)【Research Output:机构库名Aberdeen University Research Archive (AURA);研究信息系统用Pure】
–贝尔法斯特女王大学:研究门户,由Pure支持【Research Portal】
图书馆【在其中扮演什么角色】
近年发生的有趣的事情之一是,校园各种其他玩家,正围绕可能与图书馆兴趣重叠的数字信息管理开展服务日程,包括如IT【在我国可能是学校网络中心】、教学支持和大学出版社。这与另一个趋势一致,即对追踪、管理和披露机构的研究和学习成果的不断增长的兴趣:研究数据、学习资料、专业简历、研究报告和文章等等。这两个趋势交汇,意味着图书馆现在与研究办公室【在我国大约是科研处、社科处】及其他校园合作伙伴共享兴趣。由于机构本身的和公共的科学政策都对大学成果增长有兴趣,这将成为一个更重要的领域,图书馆将越来越多成为一个合作伙伴。对于机构数字资料将如何更全面地管理,与研究者身份清晰连接,研究信息管理是这个慢慢兴起视角的一部分。
【结论】
无论研究信息管理在美国是否成为一个新的服务类型,如我已经在这儿讨论过的方式,很明显,它所提出的问题,将为图书馆提供重要机会,进一步参与支持大学的研究生活。