十多天前,黑客新闻(Hacker News)上有人提问,引来一百多条回复。问题是:“几年前,好像每个人都在谈语义网是下一件大事。发生了什么吗?那地方现在还有创新工作吗?人们还感兴趣吗?”从回复看,语义网似乎已经走向了末路,其中一条大概可以说明语义网的现状:“原来(伯纳斯-李等)提出的语义网,如同去年路毙的动物那样死了,尽管还有很多装着不是这么回事。还有很多小组试图复兴最初的想法,或者如知识管理领域的很多事,他们只是简单地改变定义,纳入其他看上去类似、或许能替代的事”。多人提到其产出低,用其中一位的说法是:“所有把语义标记放在没有回报的努力上是一个愚蠢的主意”。有一位指出“语义网不像联盟,更像共产主义”,显见其因缺乏商业模式而遥不可及。
约翰霍普金斯大学的系统馆员Jonathan Rochkind在其博客上,针对该提问及回复写了博文《语义网还是个事儿吗?》,总结了语义网/关联数据的现状,对图书馆界的关联数据热提出质疑。
他首先说明: “关联数据”基本上和“语义网”谈的是相同技术,是“语义网”的一种新品牌,只是关注点有些小变化。然后指出:图书馆界正将很大精力放在尝试生产“关联数据”,而我认为关注更大的世界中正发生什么很重要。
其博文的主要观点有二:
其一,图书馆界因为视语义网/关联数据为技术发展方向而跟随,希望跨出自己的小圈子,不再创建图书馆自己的特定标准,但事实上“其他人似乎没有走向数年前人们希望的那条路”。当下反倒是图书馆及其他没有商业压力的文化遗产机构和民间组织才是探索关联数据的主体。
其二,图书馆更应该关注自己数据的质量、共享自己的数据,并建立适用的模型,而不是盲目跟风“关联数据”。
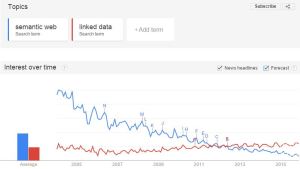
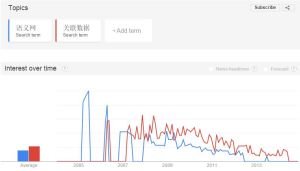
读完博文,用Google趋势对比了“语义网”和“关联数据”,前者十年间下降趋势明显,而后者呈稳中有升状态,自2012年前后超出前者;中文世界大部分时候“关联数据”在“语义网”之上,但均呈下降状态。
———-语义网还是个事儿吗?(原文摘译)———-
Bibliographic Wilderness: “Is the semantic web still a thing?” (October 28, 2014)
– GIGO(垃圾入垃圾出)
取原有同样数据转换格式为“关联数据”不一定增加多少价值。如果是以前未很好受控、未很好建模或不完整的数据,即使采用RDF它还是那样。改善数据质量,比转换格式为关联数据/RDF,可使数据增加更多的潜在价值、更多的附加利用。
– 但请共享数据
如果你的数据有价值,开发者会发现用它的途径,简单地提供已有数据,比试图转换为关联数据更便宜。你可以发现是否有人感兴趣。如果无人对你那样的数据感兴趣——不可能在你把它建模为“关联数据”后,对其兴趣就大大增加。
– 跟潮流vs做工作
部分问题是,建模数据本质上是一个上下文相关行动。没有普遍适用的模型——这里谈的是本体层的实体和关系,在数据中作为不同实体表达的对象、它们如何关联。不管建模为RDF还是定制XML,建模世界的方法对不同环境、领域与商业可能有用,也可能无用甚至不可用。……
这些不是不能解决的问题,而是有趣的问题,是图书馆作为专业信息组织应当有兴趣致力解决的问题。语义网/关联数据技术可能在解决方案中起很好的作用(尽管很难明确它们正是“这个”答案)。
对图书馆来说,有兴趣致力于这些问题很好。但致力于这些问题意味着“致力于”这些“问题”,意味着花资源在调研和研发,员工具有正确的专长与组合。不意味着盲目跟从关联数据风潮,因为(错误地)相信它已经被图书馆外(意味着“比图书馆更时髦”)的人们判断为正确的途径。
其实语义网以及关联数据在其他领域发展的还好吧
如果还好,那位博主也就不会发这么大一通感慨了。
查了下,那个网站在全球排名1814,最近三个月上升了1000多,看上去是个极有人气的网站。在上面混的,应该了解现状。
从这个视角来判断一个网站的内容,有趣
很多人不明白语义网和关联数据都只不过是对一项Web技术革命性变化的一种包装和名称而已,根本性的东西就是在HTML(XHTML)之后很大一部分内容在向RDF(各种形式的RDF,包括RDF/XML、JSON-LD等)转。当然,永远不可能所有的东西都变成RDF。这也是语义网是在传统Web基础上的发展的意思。语义Web成为趋势,必将普及,这已经是板上钉钉的事情了,除非有东西取代Web。