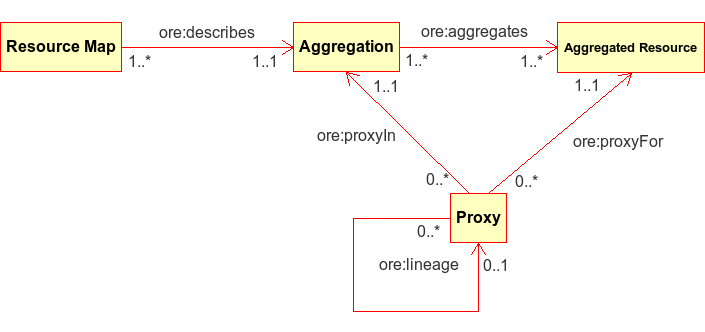
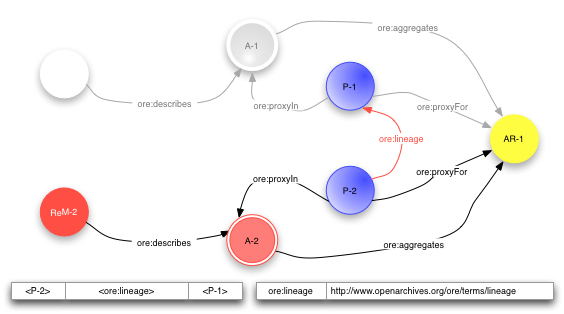
11月初BIBFRAME 2.0草案在邮件组提出,很奇怪地安静了一周,接下来一周忽然就吵得昏天黑地。特别是针对单件,有各种讨论,其中一个涉及URL。
开始的引发问题是为什么在2.0中URL作为文字(而不是标识符)。期间RSC主席Gordon Dunsire插上一脚,介绍RDA有关URL和URI讨论,基本结论是:“URI是一个thing(RDF资源),URL是一个字符串(非可解析标识符)”。对此结论,多位表示不赞同。
Karen Coyle认为URL就是URI。并且“如果你有一个URL,你不能知道它是非可解析的,直到你试着解析它……你可以自己决定你不希望解析某些构造良好的URI,把它们当成字符串,但把这些称为URL似乎不正确。”
LC的Ray Denenberg直截了当地表示,“把URL当作一个非可解析标识符是严重的错误。”在为LC编目员编写的BF的RDF简单入门中,他指出,两者“没有在解释上有任何价值的实质性区别,因此假定它们是相同的。”
OCLC的Jeff Young提供了一份W3C Note,称有助于理解URL和URI的区别。
面对质疑,Dunsire的解释是:anyone can say anything about any thing. RDA认为URL是远程访问资源的地址,这里“资源”指RDA/FRBR实体载体表现。在承认URL不是不可解析后,举例说明如果把URL处理为URI,将形成同义反复。
他的解释很长,但显然没有说服其他人。
对我来说,重要的还是仔细看看Young提供的文件。
——— URI、URL和URN:澄清和建议 ———
URIs, URLs, and URNs: Clarifications and Recommendations 1.0 / Report from the joint W3C/IETF URI Planning Interest GroupW3C, Note 21 September 2001
关于URI:
– 传统视角(1990年代中期),认为标识符(URI)可以指定资源的位置(URL)或资源的名称(URN),因此URI是URL或者URN,还可能是URC(指向资源的元数据即引用)。
– 当代视角(此文件所处的2001年),只有一个通用的URI体系,http:和urn:都是URI体系。urn:定义的URI体系子空间即命名空间,http URI即是URL。
– 附加URI(未在文中考虑的):
— 使用URI作为标识符,不标识网络资源,而是标识抽象对象(概念)或者物理对象(一本书甚至一个人)【关联数据世界中的thing?】
— 国际资源标识符IRI:URI语法扩展到非ASCII字符【2001年就考虑到了】
关于注册:
在2001年,就已有了IANA(Internet Assigned Numbers Authority)负责维护的两个标识符体系注册,目前仍在更新:
– Uniform Resource Identifier (URI) Schemes
Last Updated 2015-11-25(当年有30个;目前约300个,如ftp, http, feed, tv, z39.50)
– Uniform Resource Names (URN) Namespaces
Last Updated 2015-10-19(当年有8个,包括issn;目前有约60个,包括isbn)
文中提到未注册的命名空间如hdl:有猜测指该体系未注册,是因为拥有者不清楚应该注册为URI体系还是URN命名空间。
确实,我也不知道这两种注册的本质区别是什么。
目前很多著名的命名空间都没有注册,只在应用中声明。