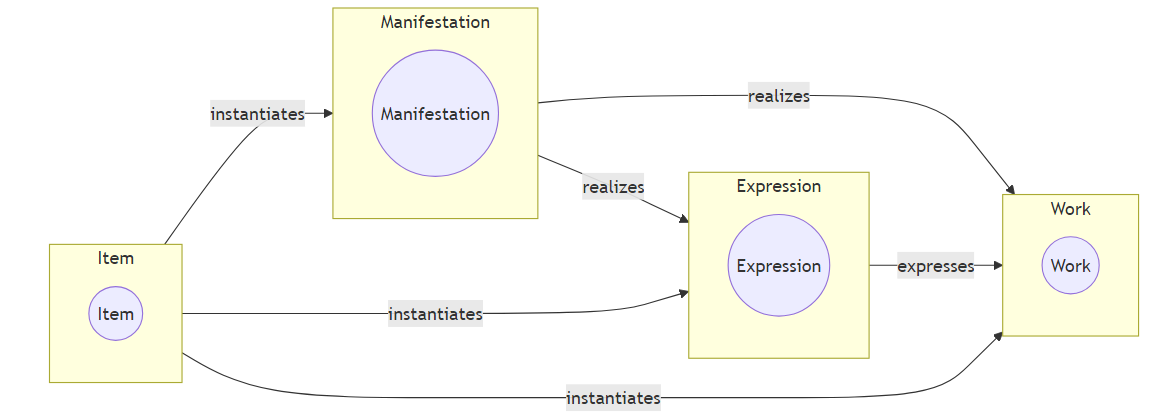
BIBFRAME词表中,Hub的定义是:作为两部作品之间桥梁的抽象资源。
BIBFRAME 2.0最初是三层模型,即“作品 Work—实例 Instance—单件 Item”。相对于《书目记录的功能需求》(FRBR)的四层模型WEMI(作品W—内容表达E—载体表现M—单件I),bf:Work对应于WEMI前两层“作品W”和“内容表达E”。BIBFRAME词表后续更新,2.1版引入bf:Hub,大致对应WEMI最上层的“作品W”,但当时bf:Hub被定义为bf:Work的子类;2.3版将bf:Hub定义为基本模型类(Basic Model Class),可以认为真正与FRBR的“作品”对应,即BIBFRAME 2模型与WEMI模型基本达成一致。参见:
- Hub:BIBFRAME模型下的超级作品(2020-6-28)/posts/2020/0628/5427
- BIBFRAME本体2.1版发布(4层确认)(2021-6-25)/posts/2021/0625/5697
- BIBFRAME本体2.3版发布(2023-12-2)/posts/2023/1202/6167
模型如此,数据则是另一回事。因为当初编目时并没有这样一个模型,数据没有相应的标识,现在要运用此一模型,需要通过算法对现有数据进行聚类处理,而算法如果没有适当的数据支撑,也是无法完成正确聚类的。就美国国会图书馆(LC)目前发布的BIBFRAME数据来看,bf:Work(=内容表达E)聚类还有差距,比如一些显然多次出版的作品的相同内容表达却都只有1个实例;bf:Hub(=作品W)差得更远,比如作品的不同语言翻译目前都视为不同bf:Hub。
日前有人在BIBFRAME邮件组提问,说自己原以为在BIBFRAME 2.0中,同一作品的多个翻译会放在一个Hub下,但从LC的BIBFRAME数据看并非如此(如作品《哈利·波特与阿兹卡班的囚徒》)。
LC网络开发和MARC标准办公室的Nate Trail回复,认可她的观点,并举《哈利·波特与阿兹卡班的囚徒》的Hub(Harry Potter and the prisoner of Azkaban,https://id.loc.gov/resources/hubs/7571ef89-f950-64a5-9a78-608b1bfdce54.html),说明bf:Hub数据来自LC相应的名称-题名规范记录(Rowling, J. K. Harry Potter and the prisoner of Azkaban,https://id.loc.gov/authorities/names/no2013059078.html),其中Hub侧栏的分面“related work” 来自规范记录(字段“Additional Related Forms”),其余分面的链接则由记录相关信息动态生成。Nate Trail认为LC需要“调整sparql查询中的一些内容,以优化事物之间的关联方式”。
相信随着算法改进,Bibframe Hub和Bibframe Work会有更好的聚集作用。
以下以罗琳“哈利·波特”系列作品(清单附后)第3部《哈利·波特与阿兹卡班的囚徒》为例,记录Bibframe Hub在2024-9-15的聚类现状。
— Bibframe Hub:Harry Potter and the prisoner of Azkaban —
《哈利·波特与阿兹卡班的囚徒》的Bibframe Hub,侧栏分面有6种,记录了改编电影,以及和“哈利·波特”系列中的前后作品,比系列中其他几种书揭示的内容更丰富:
- [1] Has Expression(有内容表达,取值为 bf:Work)
Rowling, J. K. Harry Potter and the prisoner of Azkaban
…… [名称相同的其他5条,略]
(说明)名称相同的6条是不同的Bibframe Work。
第1条,是相应的Bibframe Work,https://id.loc.gov/resources/works/21268504.html,有分面“Translation”(其他5条没有此分面),下列数十条翻译,如:Rowling, J. K. Harry Potter and the prisoner of Azkaban. Slovak(斯洛伐克语),链接的是Bibframe Hub——也就是说,不同语言翻译是不同Hub(即前引邮件组中提出的问题)。
上述6条Bibframe Work记录的侧栏分面详简各不相同,共同的是必有的“Has Instance”(有实例,取值为 bf:Instance),但其下均只有1条Bibframe Instance(如前述不合理之点)。
- [2] Related To(相关,取值为 bf:Work)
Rowling, J. K. Harry Potter and the Chamber of Secrets
Rowling, J. K. Harry Potter and the goblet of fire
Harry Potter and the prisoner of Azkaban
(说明)信息当来自[3],不同的是链接到相应的Bibframe Work。
- [3] related work(相关作品,取值为 bf:Hub)
Rowling, J. K. Harry Potter and the Chamber of Secrets
Rowling, J. K. Harry Potter and the goblet of fire
Harry Potter and the prisoner of Azkaban (Motion picture)
(说明)如前引Nate Trail所述,来自规范记录,链接到相应的Bibframe Hub。
- [4]Sequel to(续前,取值为 bf:Hub)
Rowling, J. K. Harry Potter and the Chamber of Secrets
(说明)“哈利·波特”系列系列第2部
- [5] Sequel(后续,取值为 bf:Hub)
Rowling, J. K. Harry Potter and the goblet of fire
(说明)“哈利·波特”系列系列第4部
- [6] Adapted as motion picture(改编为电影,取值为 bf:Hub)
Harry Potter and the prisoner of Azkaban (Motion picture )
(说明)小说改编为电影,是不同作品,有不同bf:Hub(与WEMI模型一致)
— 附:JK 罗琳的“哈利·波特”系列 —
- 1哈利·波特与魔法石 Harry Potter and the philosopher’s stone
- 2哈利·波特与密室 Rowling, J. K. Harry Potter and the Chamber of Secrets
- 3哈利·波特与阿兹卡班的囚徒 Harry Potter and the prisoner of Azkaban
- 4哈利·波特与火焰杯 Harry Potter and the goblet of fire
- 5哈利·波特与凤凰社 Harry Potter and the Order of the Phoenix
- 6哈利·波特与“混血王子” Harry Potter and the Half-Blood Prince
- 7哈利·波特与死亡圣器 Harry Potter and the Deathly Hallows