月初去合肥,参加全国图书馆知识组织与新一代信息服务系统数据管理专题研讨会(好长的会名)。
- 我讲BIBFRAME,包括最新进展,有今年9月欧洲BIBFRAME研讨会(BFWE 2023)EBSCO的Gloria Gonzalez关于FOLIO将如何用BIBFRAME,Maurits van der Graaf 对国际应用RDA和BIBFRAME的预测,以及Marshall Breeding去年的预测【参见:用BIBFRAME成本更高?(2023-5-23)】
会上EBSCO中国创新服务总监周奇有报告“FOLIO项目进展及案例分享”,其中两点我特别感兴趣:
- 其一,folio的Poppy版本将有MARC编目(2023 R2第2次发布)。回来查Poppy(罂粟花)计划2023-11-20公开发布,在典藏app中新增quickMARC选项,可创建新的MARC书目记录(而不仅仅是导入记录)【见:Poppy (R2 2023) Release Notes. https://wiki.folio.org/display/REL/Poppy+%28R2+2023%29+Release+Notes】
- 其二,2023年世界开放图书馆基金会大会(WOLFCon 2023)Gloria有个FOLIO与BIBFRAME的报告。回来查8月会议的这个报告,与她在BFWE 2023的报告风格、侧重各有不同。
——FOLIO的BIBFRAME相关功能——
以下概述自2个报告:
- 关联数据和FOLIO的BIBFRAME世界 Linked Data and BIBFRAME World for FOLIO / Gloria Gonzalez, Vince Bareau, Anuar Nurmakanov. WOLFcon 2023, 2023-8-23. 31 slides.
- 数据解锁:让图书馆在FOLIO中拥有丰富的联系和见解 Data Unlocked: Empowering Libraries with Rich Connections and Insights in FOLIO / Gloria Gonzalez. BIBFRAME Workshop in Europe 2023, 2023-9-20. 39 slides.
- 关键关联数据功能将于2024年进入FOLIO:
[1]BIBFRAME编辑器【Marva,关联数据编辑器;可在FOLIO内部或外部使用】
[2]基于图谱的存储【关联数据DB】
[3]连接到其他FOLIO图书馆的网络
[4]一键从MARC移到BIBFRAME【ETL引擎,即提取、转换、加载,将多个来源的数据组合到中央存储库】
[5]通过API和联合提要[syndication feeds]将关联数据发送到任何用户界面【同步推送功能】
[6]可选加入BiblioGraph的更大数据网络【使用BIBFRAME Lite;关于BiblioGraph,参见:EBSCO推出BiblioGraph(Library.Link改名?)(2023-2-6)】/posts/2023/0206/6028
- FOLIO将如何使用BIBFRAME:
BIBFRAME转换(关联数据转入/转出)
BIBFRAME编辑(书目、规范、管理数据)
BIBFRAME共享(API、同步、互操作)
BIBFRAME报告(追踪、测量、评估…)
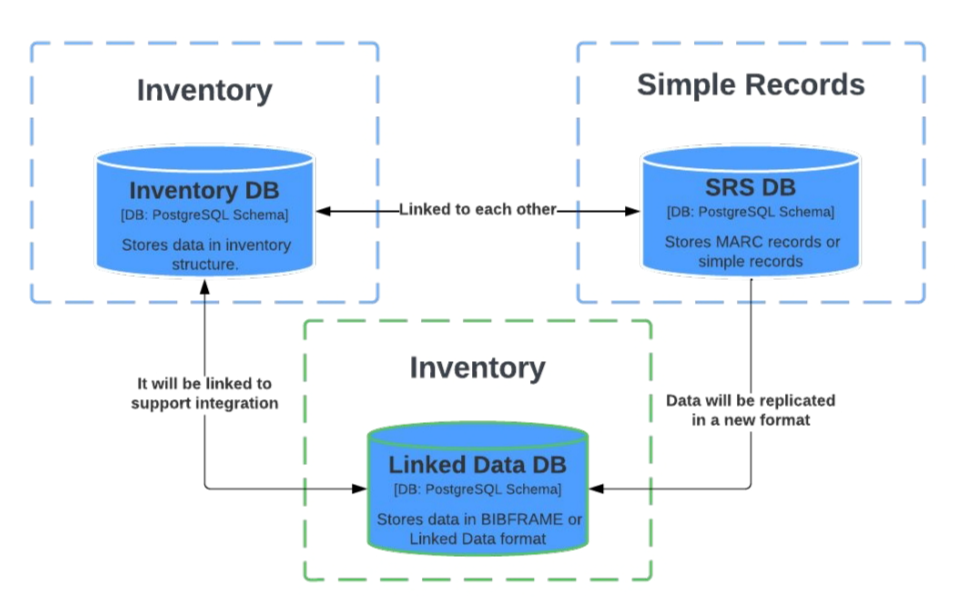
- FOLIO的关联数据核心变化:新增2个app、新增关联数据存储
[1]Marva编辑器app->关联数据模块
[2]图谱浏览器app->数据浏览模块
[3]关联数据DB(BIBFRAME存储)【FOLIO原来将MARC或其他格式书目记录导入简单记录库SRS DB保存,实际使用的是典藏DB,两个库相互链接。新增的关联数据DB将存入2个新增app生成的数据,并复制SRS DB中的数据。典藏模块将有2个存储即:1)典藏DB,2)关联数据DB,两者相互链接。】