《对象重用与交换》(OAI-ORE),此标准的名称说明了目的或功用,但“对象”指什么?这个“对象”,当指资源及其组合,在OAI-ORE中称为“聚合”(aggregations)。
“我们使用多页Web文档首页的URI来标识整个文档,我们使用HTML页面的URI提供访问一个Flickr集以识别整个图像集。但这些URI实际上只是识别这些特定页面,不是构成整个文档的页面联合,或者识别在一个Flickr聚合中所有图像的联合。本质上,此问题是,没有标准途径去描述聚合的成分或边界,这正是OAI-ORE致力于提供的。”——ORE User Guide – Primer
OAI-ORE目前为1.0版,用户指南文件包括入门、抽象模型、词表、序列化格式等:
Open Archives Initiative Object Reuse and Exchange (OAI-ORE) (version 1.0, 17 October 2008)
概要:
在Web中,“资源”指代感兴趣的任何项目,聚合则指资源的某种组合。
OAI-ORE基于语义网,以RDF图(三元组)描述Web资源的聚合。
OAI-ORE使用资源地图(Resource Map)描述聚合的成分或边界,揭示聚合本身及与被聚合资源间关系,并可选用代理(Proxy)指明被聚合资源。
OAI-ORE标准可用于网络爬虫、网络计量研究、数据交换与交互、数据重用与重构等,供机读使用。
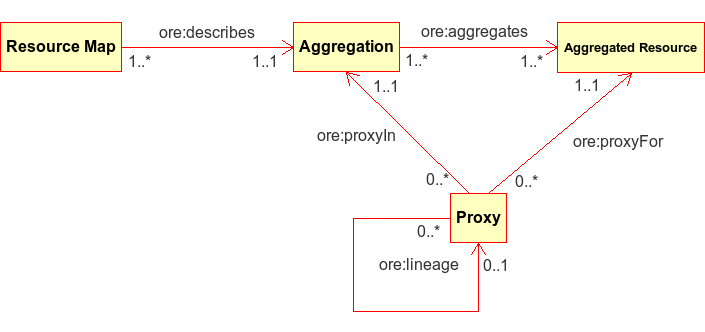
ORE模型中关键实体间关系UML图
———- ORE Specification – Abstract Data Model 抽象数据模型 ———-
聚合特征
– 资源可能在一个服务器上,也可能分布在Web上;
– 资源间关系各异,如包含、替代等;
– 资源类型可能不同,甚至由不同词表定义,如书目、目次等;
– 资源与外部资源间关系各异,如引文、镜像、译文等。
聚合举例
– 相同类型、不同项目:收藏图片集,来自不同网站;多页HTML文档,以“前页”、“后页”链接;
– 相同项目、不同格式:Flickr上的照片,有多个尺寸与分辨率的图像,另有评论等;学术出版物,以过渡页(splash page)形式存储在arXiv等中,链接到多种格式全文,另有引文链接等;
– 不同类型资源组合:研究成果集,由成果、数据、可视化分析工具组成;
– 有层次的资源组合如:叠加期刊(overlay journal),文章组合为期、期组合为卷、卷组合为期刊。
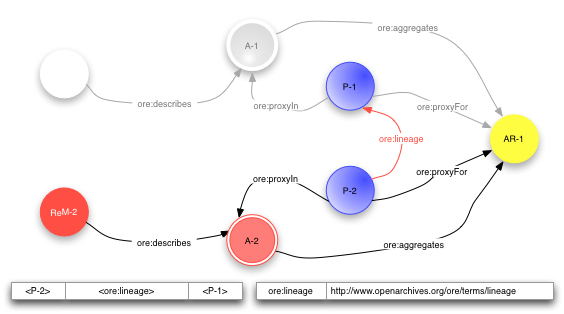
5.3代理(Proxy)【这个没完全弄明白,尤其是第3个】
特定于聚合环境的关系(非全域/全局关系,即不是在所有情况下成立),必须断言两个三元组(代理P作为被聚合资源AR的代理,在聚合A中起作用):
<P> <ore:proxyFor> <AR>
<P> ore:proxyIn <A>
用途:
– 被聚合资源间关系(如:顺序关系,只适用于特定聚合中。参考文献的顺序,对各参考文献本身不适用)
<P-1> <hasNext> <P-2>
– 外部被断言关系到被聚合资源(如:引用关系。聚合是最佳论文集,用代理表明所引被聚合资源为最佳论文)
<URI-1> <xyz:cites> <P-1>
– 链接被聚合资源(如:起源或出处,被聚合资源来源于另一个资源)
<P-1> <ore:lineage> <P-2>
对主体代理的资源地图必须包含三元组 <P-1> <ore:proxyFor> <AR-1>
对客体代理的资源地图必须包含三元组 <P-2> <ore:proxyFor> <AR-1>(两个三元组中被聚合资源AR-1相同)
———- ORE Specification – Vocabulary 词表 ———-
指导原则是在可能的情况下重用已有词表。
使用命名空间:ore(本身), oreatom; dc, dcterms, dcmitype; foaf; owl, rdf, rdfg, rdfs
自定义类与关系
– 类(4个)
ore:Aggregation 聚合;父类 dcmitype:Collection
ore:AggregatedResource 被聚合资源
ore:Proxy 代理(代表一个存在于特定聚合中的被聚合资源)
ore:ResourceMap 资源地图;父类 rdfg:Graph
– 关系/谓词(8个)
ore:aggregates 聚合;父属性 dcterms:hasPart;定义域 ore:Aggregation,值域 ore:AggregatedResource
ore:isAggregatedBy 被聚合;父属性 dcterms:isPartOf;逆属性 ore:aggregates
ore:describes 描述;定义域 ore:ResourceMap,值域 ore:Aggregation
ore:isDescribedBy 被描述;逆属性 ore:describes
ore:lineage 世系;定义域、值域 ore:Proxy
ore:proxyFor 代理;定义域 ore:Proxy,值域 ore:AggregatedResource
ore:proxyIn 代理在;定义域 ore:Proxy,值域 ore:Aggregation
ore:similarTo 相似;父属性 rdfs:seeAlso;定义域 ore:Aggregation,值域 ore:Resource
推荐的重用词表(例举而非枚举)
– 类
— DCMI类型:为资源赋予大类
— DCTerms:主要作为关系的定义域、值域
— FOAF:用于与人相关的资源,包括个人、组织和项目
– 关系(两类关系:1、资源-关系-文字;2、资源-关系-资源)
— DC元素:dc:description,dc:format(建议用MIME类型),dc:language(建议使用ISO 639-1),dc:rights,dc:title
— DCTerms:dcterms:audience(建议客体dcterms:AgentClass),dcterms:contributor(建议客体dcterms:Agent),dcterms:conformsTo(建议客体dcterms:Standard),dcterms:creator(建议客体dcterms:Agent, foaf:Person),dcterms:created(ISO8601格式),dcterms:extent,dcterms:isVersionOf,dcterms:modified(ISO8601格式),dcterms:references(建议客体Resource),dcterms:replaces,dcterms:rights(建议客体dcterms:RightsStatement)
— FOAF:foaf:mbox,foaf:name,foaf:page
— RDF:rdf:type(建议客体rdfs:Class)
— RDFS:dfs:isDefinedBy(为类规定取值词表),rdfs:label(为类规定人读标签),rdfs:seeAlso