OCLC近日发布报告:关联数据,图书馆编目的未来
来自OCLC新闻:”Linked data: The future of library cataloging” is available now on the website.2024-6-24. https://www.oclc.org/en/news/releases/2024/20240624-linked-data-position-paper.html
先让Kimi读一下pdf文件,整理核心内容如下:
- 这份文件是关于图书馆目录编目未来的报告,主要讨论了链接数据[关联数据](Linked Data)的概念及其在图书馆领域的应用前景。以下是报告的核心内容概述:
- 1. 链接数据的重要性:/ 随着在线信息量的增加,良好的元数据变得尤为重要。/ 链接数据是一种组织和连接网络数据的方式,便于不同系统和自动化服务的共享和使用。
- 2. 链接数据的定义和作用:/ 链接数据通过使用统一资源标识符(URIs)打破传统的MARC记录,使图书馆数据更易于访问和连接。
- 3. 图书馆元数据的局限性:/ 传统元数据适合已知项目的搜索,但发现潜在有价值的联系需要时间和专业知识。
- 4. 链接数据的优势:/ 链接数据可以帮助用户发现意外的新路径和资源。/ 它提高了图书馆资源的可见性,并改善了搜索结果。
- 5. 图书馆工作的转折点:/ 目前,图书馆的元数据主要在MARC记录和其他固定格式数据资源中创建和管理,这限制了它们在其他环境中的使用。
- 6. 链接数据对图书馆的好处:/ 链接数据连接并扩展了图书馆知识,促进了偶然发现,并使图书馆专家能够专注于高价值的知识工作。/ 它还使图书馆能够积极贡献于全球信息生态系统。
- 7. OCLC对链接数据的承诺:/ OCLC致力于提供基础设施、工具和专业知识,以支持图书馆在元数据演变中的过渡。
- 8. 链接数据的实现:/ OCLC正在开发链接数据产品、服务和数据集,以连接数据并提供大规模数据管理所需的资源。
- 9. OCLC的长期战略:/ 包括专业知识、数据、基础设施和工具,旨在帮助各种规模和类型的图书馆顺利过渡到链接数据模型。
- 10. 链接数据的未来:/ 链接数据为图书馆提供了连接独特工作与更多用户、合作伙伴和社区的重大机会。
- 报告最后邀请读者学习、实验、实践、成长和与OCLC一起创新链接数据,并感谢所有参与链接数据研究和技术项目的人员和合作伙伴。
- 这份报告强调了链接数据在图书馆领域的潜力,以及OCLC在推动这一变革中的作用。
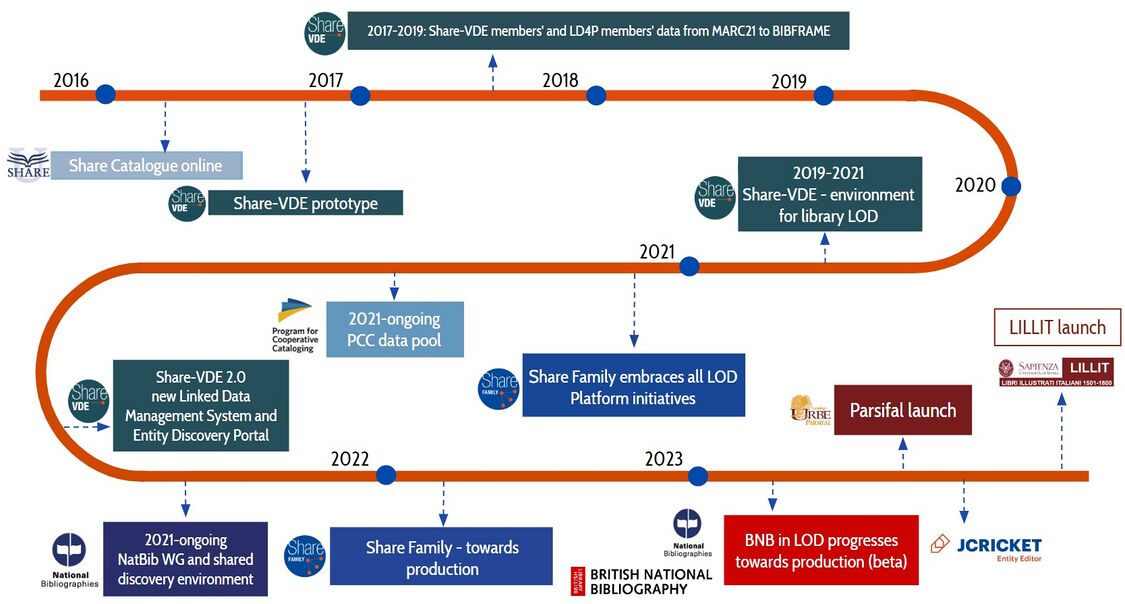
关联数据谈这么久,说它是编目的未来,并不是什么新观点。OCLC多年来一直关注关联数据,为什么突然发布一份看似平平无奇的报告?报告中说,“虽然OCLC对关联数据的研究可以追溯到十多年前,但我们刚刚开始将其集成到图书馆管理任务中”,显然是为推新产品/服务造势。目前来说,就是报告中提及的Meridian(子午线),WorldCat实体的集成服务工具(将另写博文)。
而Meridian应该只是开始,本报告“工具”部分说:“我们今天正在将链接数据集成到图书馆工作流中,同时也在为明天做计划。我们正在创建一套复杂的新工具,向现有记录和工作流添加有价值的链接数据元素,同时在可预见的将来维护并行MARC服务和应用程序。”
是不是可以这么理解——在可以预见的很长一段时间,还会有很多图书馆继续使用MARC,他们也需要让自己的目录进入关联数据世界。不用说,BIBFRAME也可以使用WorldCat实体标识符。
— WorldCat实体及关联数据标识符 —
从报告看,OCLC的关联数据战略,目前主要围绕WorldCat书目记录中的实体URI,WorldCat实体包括作品、个人、地点、事件等。上述几个网页中提供的数据是,WorldCat实体有1.5亿,已有4亿WorldCat实体URI(标识符)添加到WorldCat的MARC记录中。
年初的2024冬BIBFRAME更新论坛,OCLC有报告:OCLC为BIBFRAME所做的准备(OCLC’s preparation forBIBFRAME / Jeff Mixter. 9 slides),其中讲到OCLC在关联数据标识符及相关工具方面的进展:
- 2023年12月,已将个人、地点和事件的WorldCat实体URI添加到WorldCat记录中
- 2024年1月,开始将作品的WorldCat实体URI添加到WorldCat记录中
- [工具]2024年1月底,WorldShare Record Manager集成WorldCat实体查找和URI插入编目工作流程。/ 发布此工具的目的在于,弥合传统记录和关联数据框架之间的差距,实现数据的无缝创建和管理。此工具将为MARC编目员提供在编目时添加关联数据特征的能力,以帮助改进数据转换到关联数据,并支持已经在BIBFRAME 2.0中编目的图书馆员。
参见:2024冬BIBFRAME更新论坛(2024-2-8) /posts/2024/0208/6201