Share Family 由两家意大利公司 Casalini Libri(书商)和 @cult(软件公司)主导,始于2016年意大利多家大学图书馆的联合目录SHARE。参见:BIBFRAME 2.0实施注册新增项目(附:意大利SHARE目录)(2017-7-25)
SHARE原本是刻意选择的首字母缩略词 Scholarly Heritage and Access to Research,后来直接用作“共享”之意。2017年起公司与LD4P项目、若干北美大学图书馆共同开发Share-VDE,影响逐渐扩大。参见:Share-VDE在图书馆关联开放数据中的作用(2021-10-30)
2019年12月,不定期刊物 Share Family Bulletin 发刊,显示Share Family雏形初现。之后各期,可追踪这些年的进展。
2023年建立 Share Family网站:https://www.Share-Family.org
刊物最新为2023年12月第8期 Share Family Bulletin (2023.12 no.8),总结2023年Share Family倡议的成就和挑战,实际也概述了整个发展史。
以下为第8期翻译摘编,含本人先前相关博文链接。文中的图似乎都是从之前各演讲PPT中取来,与文字不尽配套。
把原结语移到最前面,突显Share Family的背景与态度:
【结语】通过采用BIBFRAME作为与IFLA-LRM兼容的主要本体,Share Family利用关联开放数据的潜力,促进数据池之间的互操作性,与MARC共存。
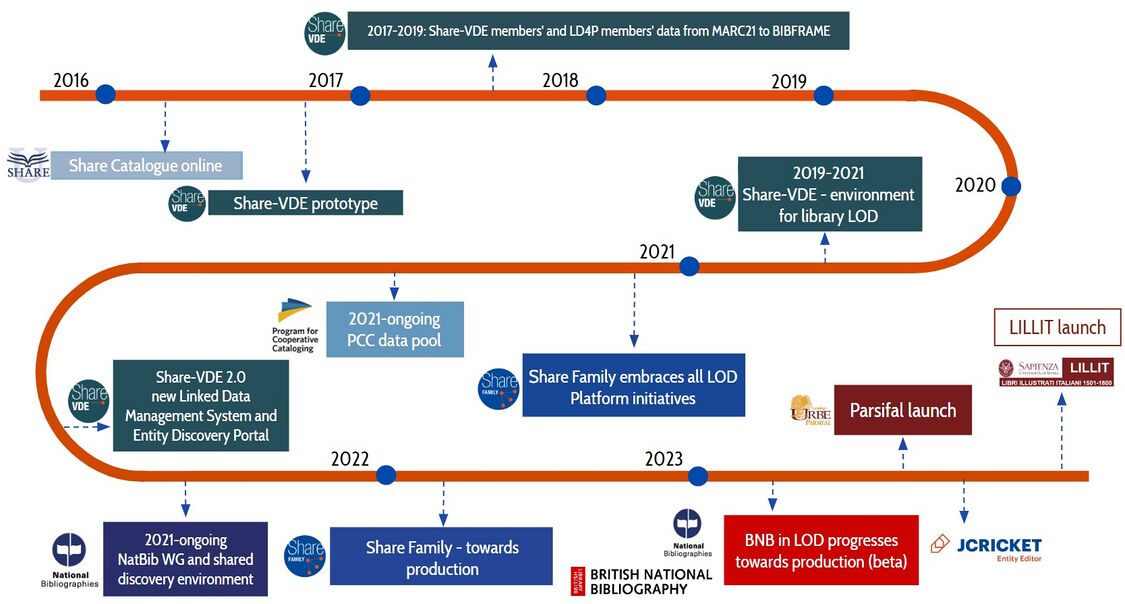
图[1]:Share Family发展时间线(2016-2023)
- 2016 Share目录上线,开始Share-VDE原型;
- 2017-2019 Share-VDE成员和LD4P成员数据由MARC21到BIBFRAME;
- 2019-2021 Share-VDE 图书馆LOD环境;
- 2021 Share Family启动全LOD平台项目;PCC数据池开始;Share-VDE 2.0 新关联数据管理系统和实体发现门户;国家书目工作组开始;
- 2022 Share Family走向生产;
- 2023 英国国家书目(beta)走向生产;JCricket【参见:JCricket实体编辑器(2023-10-16)】
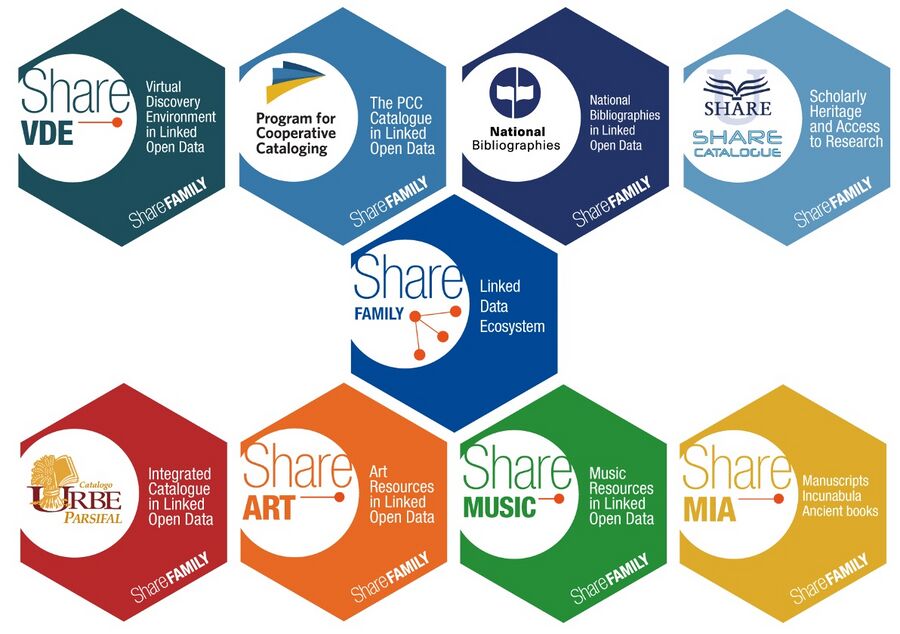
图[2]:Share Family 活跃租户和发现网站【图中没有LILLIT,有尚在开发中的3个项目Share ART艺术、Share MUSIC音乐、Share MIA手稿与古籍(LILLIT或归入此)】
- Share-VDE(虚拟发现环境)https://www.svde.org/
- SHARE目录-意大利大学图书馆网络 https://catalogo.share-cat.unina.it/sharecat/clusters?l=en
- PCC数据池-关联开放数据中的合作编目(PCC)目录计划 https://pcc-lod.org/ (2024初数据将重新索引)
- 关联开放数据中的国家书目 https://www.natbib-lod.org/(2023英国国家书目beta上线 https://bl.natbib-lod.org )
- Parsifal-URBE联盟(罗马教会图书馆联盟)的LOD门户网站 https://parsifal.urbe.it/parsifal/?l=en
- LILLIT-意大利插图书籍门户网站,提供16至18世纪印刷的意大利版本的关联开放数据描述和插图 https://lillit.share-family.org/lillit/?l=en
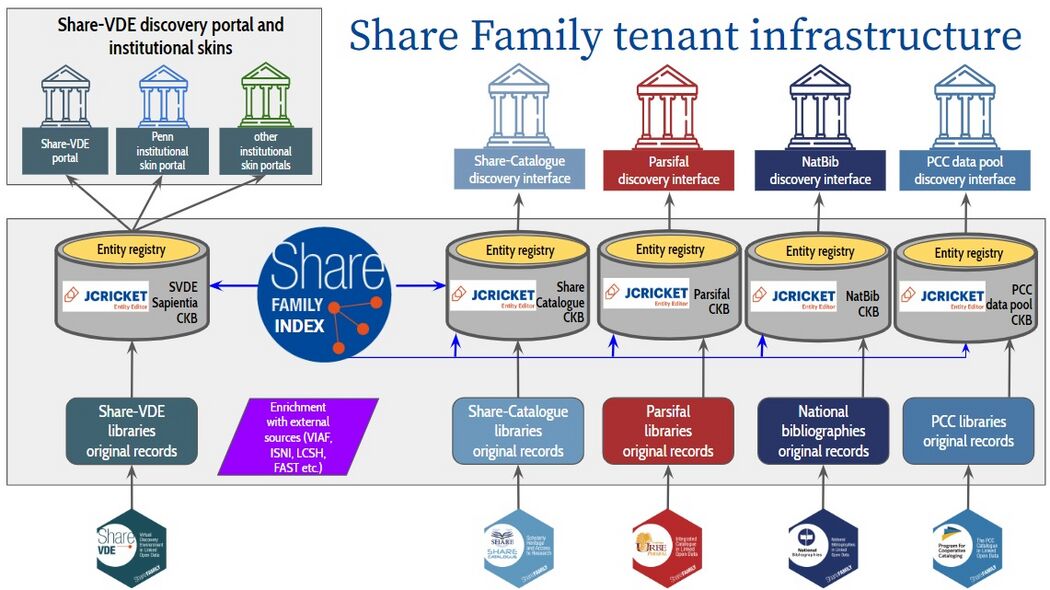
图[3]:Share Family 租户基础架构【以 SVDE Sapientia CKB 中央知识库 为中心】
- Share Family索引 -> SVDE Sapientia CKB/实体注册 -> Share-VDE发现端口和机构皮肤/各租户门户
- Share Family索引 -> 各租户CKB -> 各租户网站
- Share-VDE图书馆的原记录 -> SVDE Sapientia CKB
【工作组/列举部分】Share-VDE和Share Family工作组,由咨询委员会指导:
- SEI–Sapientia实体识别工作组:致力于创建Share-VDE本体(BIBFRAME的扩展)https://doi.org/10.5281/zenodo.8332350【参见:Share-VDE本体:BIBFRAME扩展(2023-10-15) /posts/2023/1015/6147】
- 用户体验–用户界面工作组:测试和使用Share-VDE 2.0测试版和国家书目门户网站
- 国家书目工作组
【第三方整合】
Share Family技术的发展包括将LOD平台产生的数据与外部系统相互集成的能力,尤其是与本地ILS和图书馆服务平台以及权威来源的集成。
- 关于与ILS和LSP整合,值得一提的是一些进步:
-由SVDE AIMS工作组设计并由斯坦福大学图书馆进一步投入的基于MARC的工作流程的新规范服务已经完成,可供愿意测试和使用它们的机构使用。此外,AIMS工作组将于2024年重新召开会议,分析和设计基于RDF/关联数据的工作流的规范控制功能;
-Alma流通API与地方图书馆服务的整合工作基本完成;
-与原生BIBFRAME编目编辑器Sinopia的集成正在进行中:来自Sinopia将由Share-VDE过程聚类的传入RDF数据的解析器正在开发中;
-已经分析了与FOLIO ILS的连接,以将FOLIO典藏数据与Share-VDE数据相关联,并将JCrick用户界面集成到FOLIO中。Share Family团队的Andrea Gazzarini和WOLFcon 2023的Index Data的Sebastian Hammer提出了一个通过FOLIO进行ILS/LSP交互的可能模型,以在相关数据社区内讨论如何寻求这种联系。
- 关于与规范系统整合,正在调查几个数据来源,在某些情况下,已经完成了初步整合步骤:
-LD4P提问规范(Questioning Authority)查询工具;
-用于相互丰富实体ID的Wikidata(最初的规范由SVDE工作组制定);
-用于相互丰富实体ID的ISNI(初始规范由SVDE工作组制定)。
【UNIMARC-BIBFRAME转换】
SHARE目录倡议已经完成了UNIMARC-BIBFRAME直接映射和转换的工作(没有通过MARC的中间步骤),并将通过将得到丰富和记录的Wikibase实例与关联数据社区共享这项工作https://unimarc2bibframe.wikibase.cloud/。【2024/1/5内容为空】
【非拉丁文字丰富LOD平台】
- 2024年国立台湾大学图书馆将加入Share Family,由国立台湾大学图书馆提供的数据将由LD4P非拉丁文字资料亲和小组进行测试;
- 正在使用一个支持阿拉伯文字的测试门户进行实验